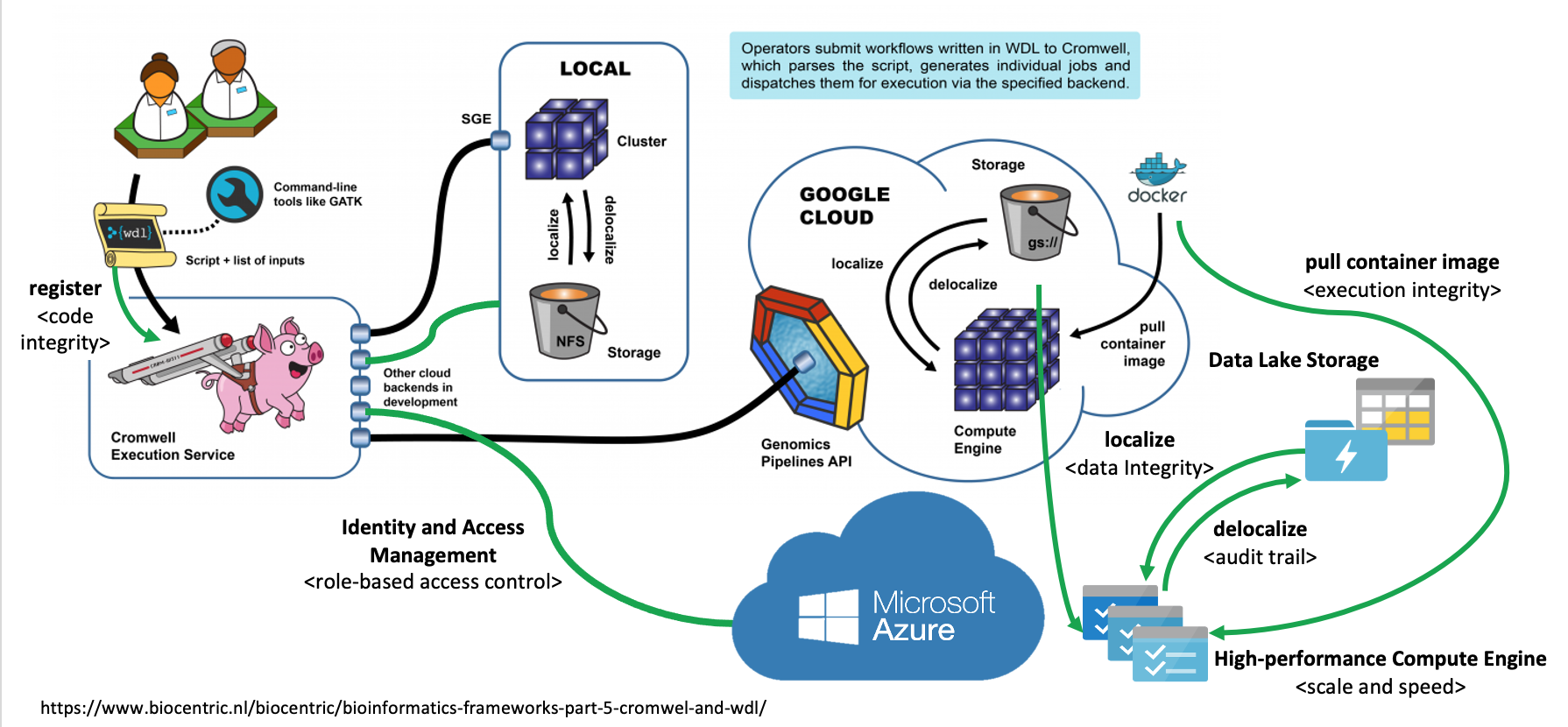
Workflow engine#
The SeqsLab Workflow Execution Engine (Seqslab WE2) is extended from the Cromwell engine, which executes workflows described in the workflow description language (WDL). Furthermore, the SeqsLab WE2 also delivers the following benefits:
On-demand Spark cluster
Seqslab WE2 requests a parallel computing cluster for each task execution based on Apache Spark (
 ), which enables you to dynamically configure the Spark properties ().
), which enables you to dynamically configure the Spark properties ().Cluster reuse
The processes of provisioning resources from cloud service providers and of establishing a Docker environment typically take some time to complete. This is particularly true when runtime attributes are actually configured not just at the task level but also at the workflow level. To address this, SeqsLab WE2 supports dynamic runtime attribute settings for better resource utilization.
Implicit and dynamic data parallelization
The SeqsLab management console provides users with an interface to easily configure implicit and dynamic data parallelization settings at the task level. By defining the inputs and outputs, you can parallelize the task computation without complicating the WDL commands and structures.
Output management
Once output is specified in a WDL task session, SeqsLab WE2 saves the data to the specified filesystem and registers the Data Repository Service (DRS) records.
Backend providers#
SeqsLab WE2 currently supports two main backends. You can either run your WDL locally on the cloud. However, in certain situations, a hybrid of both backends may be used.
Cloud backend: Azure Batch
SeqsLab WE2 uses Azure Batch (
) as the main backend for cloud-based scenarios.Local backend: Kubernetes
For use cases that require analyses to be executed on private resources, SeqsLab provides a local backend using Kubernetes (
).Hybrid backend
SeqsLab WE2 also enables you to submit tasks or workflows to either a cloud or local backend based on your compliance or operation needs. The following image shows how SeqsLab WE2 communicates with both local and cloud backends in the same run.